Ready to create impactful Data Products that consumers love? Join the Waitlist
Data is important
The best orgs in the world use data to set goals and evaluate decisions. They make it their competitive advantage.
If you can’t measure it, you can’t improve it. If you’re not improving, you’re dead.
- Business Analytics: What It Is & Why It's Important | HBS Online
- The Age Of Analytics And The Importance Of Data Quality | Forbes
- How does a Data Product Strategy Impact the Day-to-Days of Your CMO, CDO, or CFO
- Metric Trees for Product Impact
- Computing Propensity to Churn | GitLab DBT
- Metrics Driven Engineering Leadership at Netlify
- 15 Signs You Have A SaaS Metrics Problem (and How to Fix it) with Dave Kellogg
- Becoming Data Driven, from First Principles
Metrics trees, also known as KPI trees, show the relationship between the key metrics in a business, from the overall goal down to all the metrics that influence it.
We’ve found that choosing the right metrics and focusing on the team rather than the individual can motivate the entire team to consistently deliver great results.
Data drives accountability, transparency, and trust. Data cuts through opinions, charisma, and bias. It is the great equalizer, and the best chance we have at improving our teams, our organizations, and our world.
Data must be of high quality to be useful...
When data is unreliable, analytics efforts are at best ineffective, and at worst actively hurting the business.
An organization can have the best ML models, the greatest developer experience, and a streamlined production process– but throw garbage data into this pristine system, and you will still get garbage results.
...but implementing data quality is hard work...
There's a wide variety of tools in the quality toolkit, and each one takes focus and time to implement well:
- Data Quality Score: The next chapter of data quality at Airbnb | by Clark Wright | The Airbnb Tech Blog | Nov, 2023 | Medium
- Modeling and CI/CD w/ DBT
- Contracts
- Data Observability
- Anomaly Detection
- Data unit testing
By the way, that's not just true of quality in data - all reliable, fault-tolerant, high-quality software is expensive.
...and quality does not necessarily imply value.
The most sophisticated quality measures in the world cannot guarantee that a dataset solves a real problem or delivers business value.
It’s important to “build the thing right” and engineer for quality, but the best teams are also digging deep to ensure they are “building the right thing”.
Failing to solve the right problem can sap 50% or more of a data team’s time...
Pre-Production Analytics
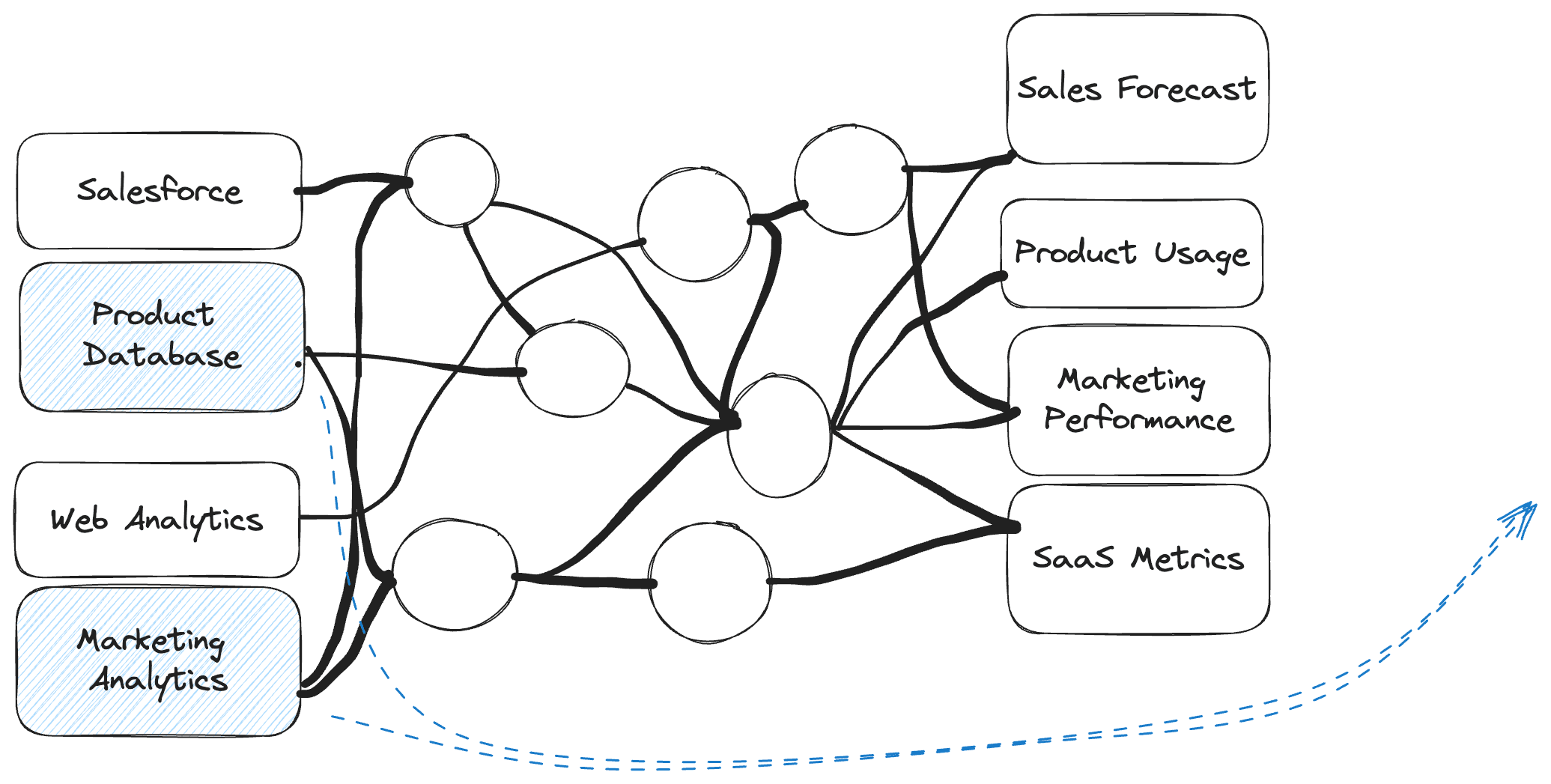
- Pre-production Analytics: When Modeled Data Doesn't Quite Cut It
- Impact: Low quality data reaches stakeholders
- Impact: Multiple sources of truth scattered across notebooks and SQL scripts
- Impact: Privacy, security, and compliance concerns
- How to gain control over shadow analytics
Unused Models
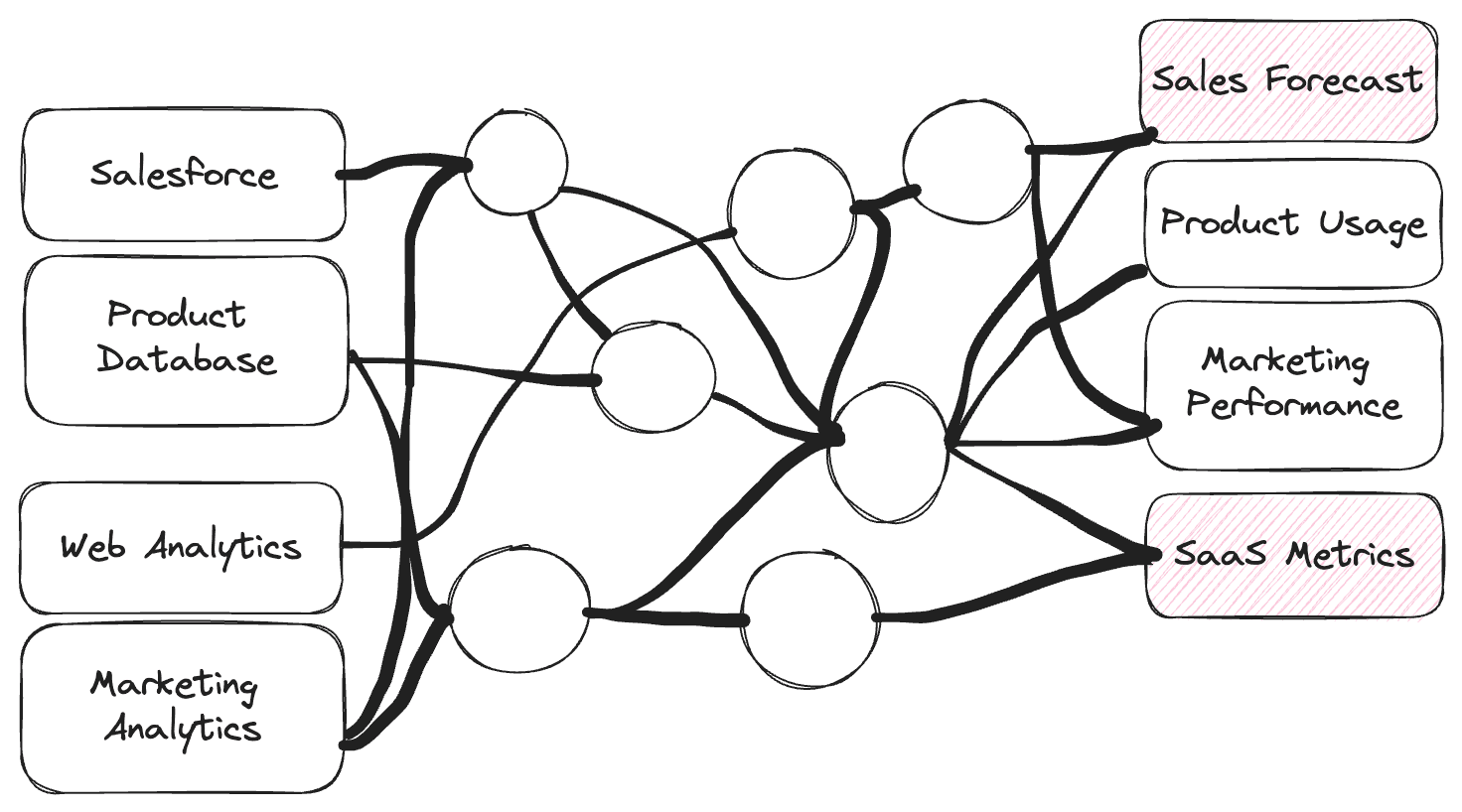
- Unused Models: When Production Data Missed the Mark
- Impact: Cost of unneeded compute / storage
- Impact: Slower dev cycles and cognitive complexity
- Impact: Maintenance overhead including 😦 unnecessary 2am pager alerts for jobs feeding unused datasets
Post-Production Complexity
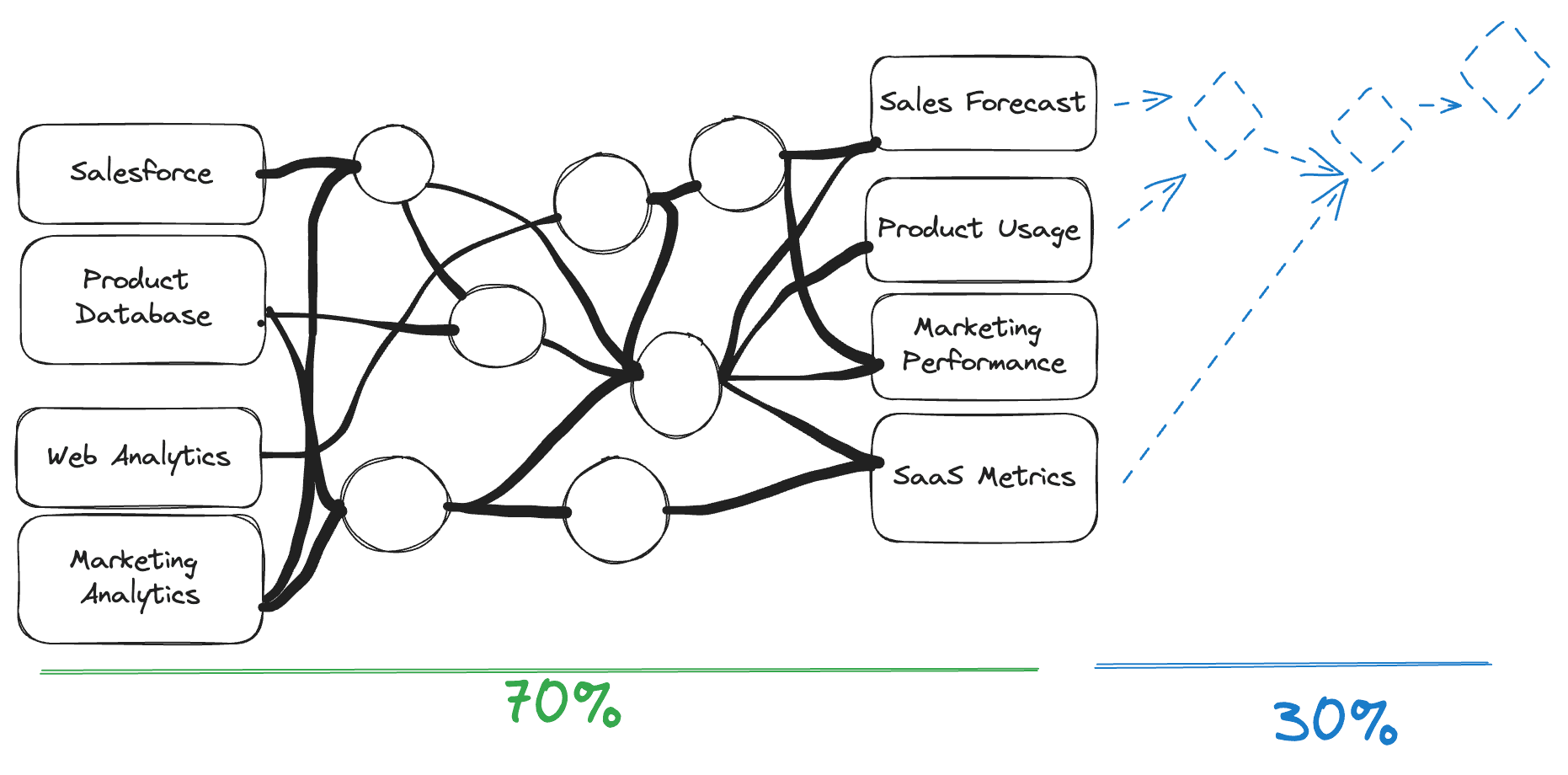
- Post-Production Complexity: When production analysis sprawls back into notebooks and SQL scripts
- Impact: Low quality data reaches stakeholders
- Impact: Multiple sources of truth scattered across notebooks and SQL scripts
I’ve had every single one of these problems for the last ten years…these things are the bane of my existence on a weekly basis
...so the best teams are bringing a Product mindset to data.
- Run Your data team as a product team | Coalesce 2020 | Youtube
- Data Product Teams : Best Practices for a Modern Data Team | Tomasz Tunguz
- Run Your Data Team Like A Product Team - Locally Optimistic
- The Data Product Manager - Locally Optimistic
- Don't Tell Your Data Team's ROI Story | Hex
- Building more effective data teams using the JTBD framework - Locally Optimistic
- Hello Product Data Team, Goodbye Ad-Hoc Work - Locally Optimistic
- Why Your Company Needs Data-Product Managers | HBR
- https://www.linkedin.com/feed/update/urn:li:activity:7127687908412526592
- Ramp's $8 Billion Data Strategy
There is a better way to build and run a data organization: run it as if you were building a Data Product and all of your colleagues are your customers.
Not enough effort has been made to understand the people using data products, what they want to get done, and the broader context in which they operate.
Always ask your stakeholders what they actually look at to make decisions. You might think and hope it's the gorgeous looker dashboard based on beautifully kimball-model DBT, but oftentimes it's not...it's on us as data leaders to look at what people are actually using to make decisions
Outside the data world, product managers are equipped with state-of-the art tools and techniques...
- What's in your software stack --- Product, Design, Analytics, DS, Research, and more
- The Role of Analytics - Silicon Valley Product Group
- Marty Cagan - Transformed: Moving to the Product Operating Model at just product 2023
- 20 Best Product Analytics Tools & Software In 2023
If you don't measure a new feature, why did you release it anyway?
…but data teams lack dedicated tools for this.
Despite the fact that Data Teams are essential to making product analytics happen, the state of the art in "run your data team like a product team" looks something like:
Good Data Product Tooling should…
Automate 80% of data product discovery
- Which are the most complex queries and analyses running on top of my production models?
- Who is running them? Let's talk to them and find out why.
- Which queries are using pre-production or lower quality data?
- How often is that data reaching stakeholders? What can we learn from consumers or pre-production data?
- What % of analyst and data science work is using production, high quality data?
- How is this number trending over time?
- This is the number one metric for understanding the progress and velocity of a data modernization initiative.
- Which models have low or no adoption?
- Do we need to educate consumers? Adjust the models? Deprecate them?
Automate 80% of data product delivery
- What steps can I take to move complexity out of notebooks and sql scripts and into quality, monitored pipelines?
- What would an initial draft of that model look like?
- What existing or similar models might serve this use case?
- What pre-production queries are good candidates to migrate into high-quality production models?
- What would an initial draft of that model look like?
- What existing or similar models might serve this use case?
- Which models can potentially be pruned automatically?
Ready to create impactful Data Products that consumers love?
Join the Waitlist