Pre-Production Analytics
When Existing Modeled Data Doesn't Quite Cut ItThis is the first in a series of blog posts about challenges teams may face when modernizing their data stack and ETL pipelines. We'll focus especially on problems in which, despite every effort being made to produce high-quality, reliable data, somehow stakeholders end up receiving low-quality or unreliable data. See also:
In this post I'll tackle "Pre-Production Analytics" and how it can undermine trust and slow down a modernization effort. Pre-production analytics describes when analysts and stakeholders use datasets other than the available high-quality production data. Some examples might include:
-
Querying a raw or staging table to build a report, and then publishing that report regularly to stakeholders
-
Grabbing data directly from an upstream system like Salesforce, HubSpot, or a product database
-
Building and delivering a complex notebook analysis on raw files in a data lake
If you're familiar with Shadow Analytics, pre-production analytics is a flavor of shadow analytics, similar to but distinct from Post-Production Complexity. In this post, I'll explore some causes of pre-production analytics, the impact on both stakeholder and data teams, how to detect when it's happening, and how to approach fixing it. Spoiler: while pre-production analytics can be a source of a lot of headaches for data teams, it's also a valuable signal that can help data teams better understand their downstream users and deliver better data products.
What's "production data"?
For the sake of this post, 'production data' means data cleaned, prepared, and modeled by data/analytics engineers, benefiting from quality measures like:
-
Version controlled, peer-reviewed DAGs/pipelines, including any or all of:
-
A classic or homegrown ETL system
-
A modeling tool like DBT
-
A dive into all these measures and their value is outside the scope of this post, so I'll assume you're at least familiar with a few of these measures and why a data team might want to implement them. We can consider a very simple example pipeline that combines some data from salesforce and a product table to build a list of active opportunities and how likely they are to close. This feeds a BI dashboard used by sales leaders.

Let's say our hypothetical data team ships this model, high fives their stakeholders, and moves on to the next thing. Weeks later, they hear a complaint - some extra records are showing up in the sales opportunity data. When digging in, it turns out that some of the report logic had been changed. Stakeholders wanted to see data about a brand new feature in the prodct database that hadn't yet been integrated into the pipeline, and so the report was modified by a sales analyst to pull in that new data, via some queries running in a notebook.
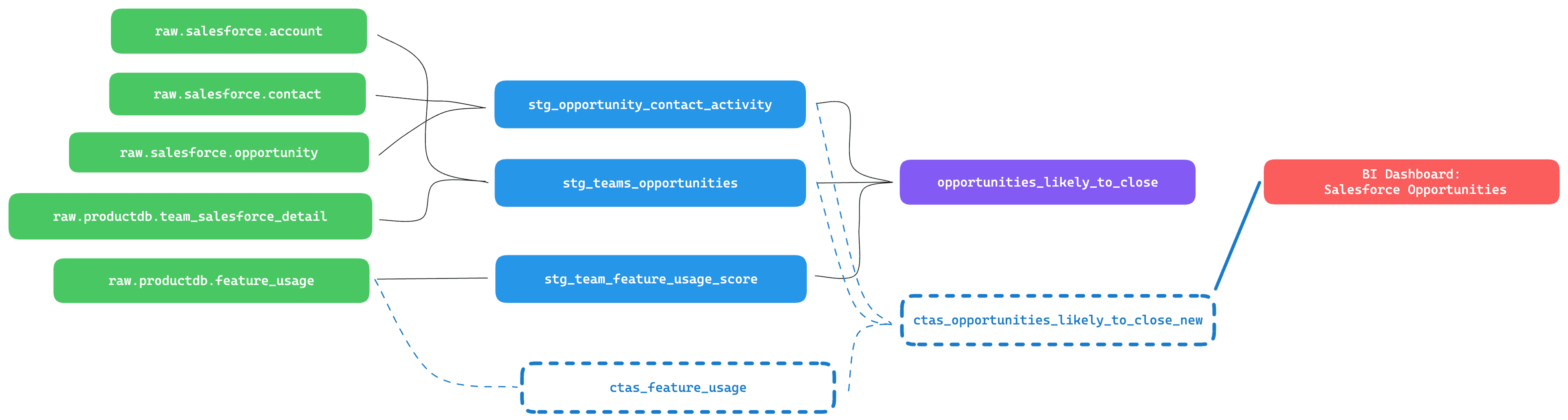
You're probably guessing why this can be a problem.
The Impact of Pre-Production Analytics
To start, you might be wondering "why do I care?" or "how does this affect me?". Historically, the biggest alarms I've heard are around security and compliance implications, but in talking to a lot of data engineers over the past few months, we've found it's broader than that. Pre-production analytics should primarily scare teams because it presents a risk that despite every effort to clean/test/monitor data, low-quality data still reaches stakeholders. This means all that effort to engineer high-quality pipelines is for naught, and the company's trust in a data team's ability to reliably deliver truth and insight is undermined. Instead, stakeholders are back to having hopefully-good-enough data, and almost certainly grappling with multiple sources of truth about "what happened" or "how is initiative XYZ doing". Beyond that risk, teams should also consider:
-
Incidents - When these pragmatic queries inevitably break due to upstream data model changes, data teams can get dragged into hours of complex debugging. Ideally lineage, contracts, and change control can help prevent these unexpected breakages, but remember, these pre-production queries are running outside of our core pipelines. Engineers are generally collaborative people and want to help wherever they can, and most of them are really really good at SQL. When the sales forecast breaks, they tend to jump in and help debug queries they 1) didn't write and 2) didn't know were running. In talking to data engineering teams, we've found that these sorts of incidents can sap 25% or more of a data team's time, time that could be spent investing in new models and additional quality measures.
-
Security/compliance - We'll assume that even when analysts access pre-production data, it's done in a safe way that doesn't expose sensitive data like names, addresses, and other PII. However, it's worth calling out that one of the big benefits of an engineered data pipeline is cleaning and obfuscating these sensitive fields, and grabbing pre-production data risks bypassing all those safeguards.
-
Undermines Modernization Effort: Despite a data team having invested heavily in quality, continued incidents mean that trust in the team as a whole remains low. From within the team and from outside it, it can feel like progress is not being made. This can lead to hard questions about the value and effectiveness of the team's efforts.
-
Upsides - While this is primarily a post about the challenges of pre-production analytics - it's worth noting that there are some upsides. For starters, you could spin it as a positive that analysts were able to move fast and get what they need. There is a short-term efficiency gain in letting teams at least explore pre-production data to prototype reports and better understand how it's being transformed. The other upside, which we'll get deeper into later, is that pre-production analytics can be a valuable signal for data teams tasked with understanding the needs of their internal customers and how they use data.
Why does Pre-Production Analytics happen?
There can be a number of causes of pre-production analytics. At the core, pre-production analytics happens when, from an analyst or stakeholder's perspective,
-
No model exists that solves a specific problem - if a specific report or problem doesn't have a production model that serves it, then data consumers have no choice but to solve their problem with pre-production data. For example, your data engineering team might be 20% through a migration to modern modeling and quality tools, with 80% of use cases still directed to older systems. Alternatively, models may have been shipped that are missing columns or records, and so even though a model exist, it's not usable by downstream consumers.
-
Data consumers are untrained on the production model - Sometimes it's a simple matter of education. The model exists, but downstream users don't know about it, or don't know how to use it effectively, so they fall back to what they know.
-
Constantly evolving data model and needs - Even if a model solved a key problem 3 months ago, as products/features/processes/teams evolve, consumers may find themselves with new problems or additional needs that are not met by the current production models.
-
Lack of Consumer --> Data communication - In a perfect world, a stakeholder or analyst might prototype a query against pre-production data, and then send a ticket over to the data team to add that query to the production workflow. In our experience however, that last communication step, the writing down what changes are needed, rarely happens. Instead, that query simply becomes part of someone's workflow until it eventually breaks.
Detection
There's a few ways to get a handle on Pre-Production Analytics, although to date there haven't been dedicated tools for detecting this.
Surveys - as outlined in Stakeholder surveys, you can send regular surveys out to analysts and stakeholders to get a better understanding of how often they need to work around production models and get things from upstream data. You might include a question like "On a scale of 1-5, how often can you get what you need from production tables?" Survey results might be used to drive further discovery conversations about how data is being used in practice.

Audit logs - The more holistic approach here would be to review audit logs in your database, to understand what's being used and by whom. There are some scrappy approaches that use regex to develop a basic understanding, as well as more complex approaches using a full-fledged SQL grammar.
Remediation and Prevention
You may notice that all the reasons why this happens are product misses - it's not that we didn't deliver reliable data, it's that we failed to deliver data that solves the end users problem.
I know it can be easy to get mad and blame downstream users for "breaking the rules", especially when you or your teammates just burned half a day debugging some complex pre-production query that was put into circulation without your knowledge. You may be tempted to go out and find or build solutions that enable you to lock down pre-production tables and ensure consumers only have access to production models or a semantic layer. While "lock everything down" is an option here, we've found that good people will always find a way to get the data they need.
My advice - when your users don't use the production stuff, don't get mad, use it as a learning opportunity. Treat your analysts like internal customers, and every instance of "shadow analytics" as a signal that your users need something that you're not providing. It's an invaluable chance to better understand what analysts and stakeholders need and what truly useful production data would look like.
I'll say it again. The best way to prevent pre-production analytics from handicapping your data quality efforts is to get to know your users and solve real problems. More generally, run your data team like a product team! There's a number of great posts on this from across the web that you can check out if you want to learn more.
-
Don't fall for the "faster horse" problem - listen not to the solution people are asking for, but rather understand the problems that need solving