Post-Production Complexity
Wrangling complex logic outside core pipelinesThis is the second in a series of blog posts about challenges teams may face when modernizing their data stack and ETL pipelines. We'll focus especially on situations where, despite every effort being made to produce high-quality, reliable data, somehow stakeholders end up receiving lower-quality or unreliable data. See also:
Introduction
Data teams ship data so that it can be analyzed and used to make decisions. As an engineer, you review all your data sources, robust ETL pipelines, and production kimball-modeled data, and think, "We're doing great. We've delivered high-quality, reliable data to our stakeholders."
Stakeholders and analysts pull up these models in their BI tools or notebooks.
They get insights and value.
All is as it should be 🧘
Enter Complexity
But then one day, something unexpected happens.
You get tapped to help troubleshoot a python notebook query that stopped working overnight. It's over 2000 lines and touches 16 tables. Unbeknownst to you, it's been being run nightly and mailed to the entire sales team.
It turns out that Stakeholders are building core workflows and running pretty complex analyses on top of your data. It is at this point you may realize that you've only solved their problem half-way. You're hitting a common problem in data: Post-Production Complexity.
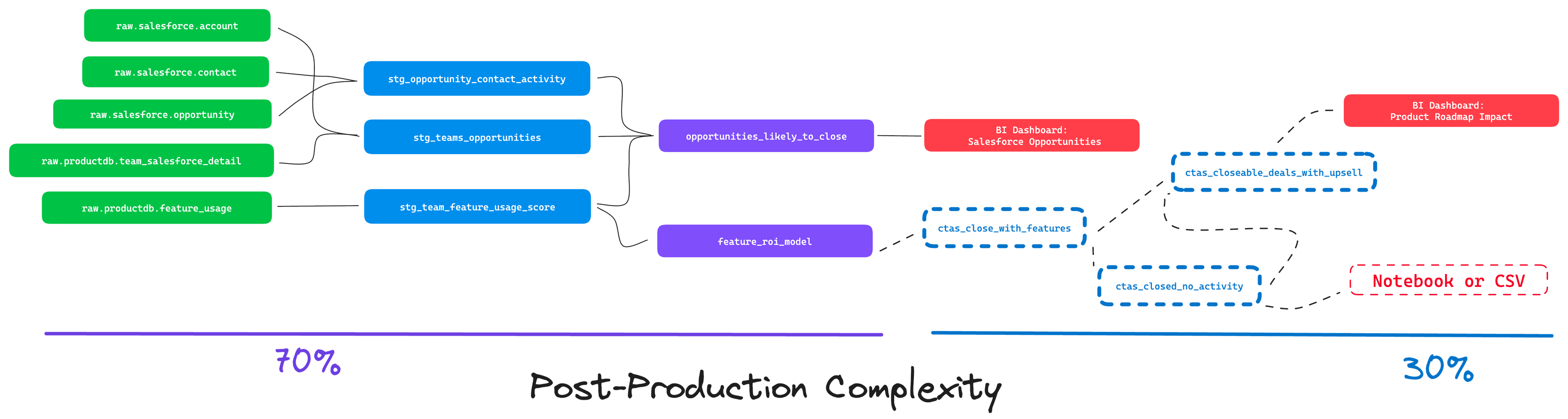
Post-production complexity often goes unnoticed until it becomes the source of broken reports, confused stakeholders and prolonged firefighting. Post-Production complexity arises when large queries and data analysis tasks are built on top of existing production infrastructure. Analyses in scripts and notebooks generally don't benefit from all the quality measures in place for production pipelines. Today, we're diving into post-production-complexity's impact, causes, detection methods, and remediation strategies.
Post-Production complexity arises when large queries and data analysis tasks are built on top of existing production infrastructure.
Orienting Ourselves
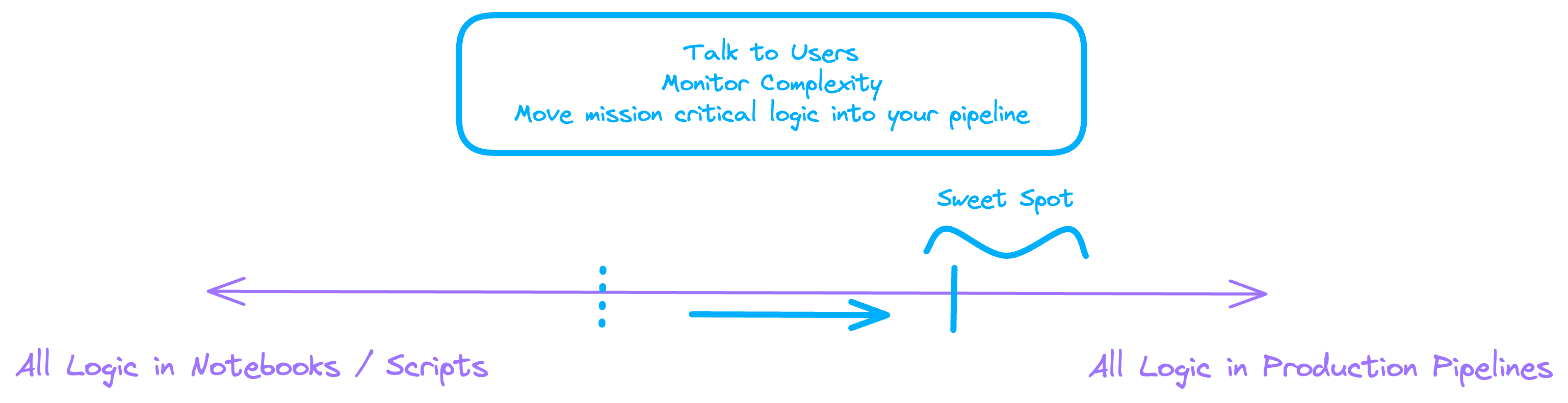
It can help to model a data warehouse with a spectrum from "all logic in notebooks" to "all logic in ETL/ELT Pipelines":

If you're new to a modern data stack, you're probably starting out all the way to the left -- that is, most of your business logic lives in one-off scripts, legacy ETL jobs, notebooks, or spreadsheets.

As you modernize and add measures like Modeling, CI/CD, Contracts, Testing and Observability you'll have some subset of your warehouse traffic coming from higher-quality, production models.
You're adding quality. This is good.

But the goal (hopefully) was never to move everything into pipelines - nobody wants a world where the only way to get new data is to build a pipeline that takes days or weeks to deliver. That would put you in Too Slow, Not Enough Exploration

Good data teams know that exploration, prototyping, and experimentation are all important parts of the data lifecycle. This exploration process helps you decide what should be made production-grade later.
So then, the sweet spot is a balance between exploration and production:

The challenge is when valuable logic lives outside production in the long term. When a 2000-line query is found to work well for a use case, sometimes it just gets run in a notebook once a week, or becomes ad-hoc SQL powering a BI dashboard. That logic never ends up being pulled up into production pipelines with quality, testing, etc. If this happens a lot over time, the makeup of logic powering critical data drifts back into a blend of "some stuff is in models, some stuff is in notebooks, some stuff is in scripts, some stuff is in dashboards, and some stuff is in spreadsheets."

Although your production logic is monitored, tested, version controlled, contracted, there will be business-critical workflows that rely on data coming from 70% production logic, and 30% post-production (read: untested, unmonitored, uncontracted) logic.
Impact of Post-Production Complexity
Post-production complexity occurs when complex queries or analyses are executed outside the regular, monitored production pipelines. This situation presents two primary challenges:
-
Risk of Low-Quality Data Reaching Stakeholders: Complex queries running outside standard workflows risk bypassing quality checks, leading to potential data unreliability.
-
Extended Incidents and Debugging Challenges: When these complex queries break, data teams face extended incidents and unfamiliar debugging challenges.
-
Undermines Modernization Effort: Despite a data team having invested heavily in quality, continued incidents mean that trust in the team as a whole remains low. From within the team and from outside it, it can feel like progress is not being made. This can lead to hard questions about the value and effectiveness of the team's efforts.
Despite a data team having invested heavily in quality, continued incidents mean that trust in the team as a whole remains low. From within the team and from outside it, it can feel like progress is not being made.
Causes of Post-Production Complexity
The root cause of this complexity is often a gap between delivered data assets and the actual needs of analysts, leading data consumers to build additional analyses. This extra layer of complexity usually remains outside the production pipelines due to a lack of communication.
-
Failure to deliver on requirements: It could be that the requirements were poorly articulated, proper problem discovery was skipped, or even just that the thing that was shipped didn't work as expected. When the shipped model doesn't fully solve the problem, more analysis will be needed in post-production.
-
Constantly evolving data model and needs - Even if a model solved a key problem 3 months ago, as products/features/processes/teams evolve, consumers may find themselves with new problems or additional needs that are not met by the current production models.
-
Lack of Consumer --> Data communication - In a perfect world, a stakeholder or analyst might prototype a complex query, and then send a ticket over to the data team to add that query to the production pipeline. In our experience however, that last communication step, the writing down what changes are needed, can get dropped. Instead, that query simply becomes part of someone's weekly or monthly workflow until it eventually breaks.
Detection of Post-Production Complexity
Define Complex - Decide on a threshold for what constitutes a "complex query" in your organization. This threshold will vary depending on the size of your team, the number of analysts, and the complexity of your data. For example, a 2000-line query might be considered complex for a small team, but not for a large team with complex use cases. You might consider any of the following dimensions:
- Number of
SELECTexpressions - Types of aggregations
- Levels of nesting
- Number of tables/schemas accessed
- Mixing of grains
If you want some inspiration, go look at the last few queries that led to incident-worthy breakages. Once you have your definition and threshold, you can ingest your warehouse's audit log to monitor for complex activity. You can use tools like antlr or sqlglot to do the heavy lifting of parsing SQL queries.
Go Beyond SQL - Complexity isn't limited to queries though, it can also live in pandas pipelines, spark jobs, and a myriad other places, all at least as fragile as a complex SQL query. As data teams, we need to be aware of what's happening with the assets we ship. This means, yes, you'll need to talk to your users and stakeholders and understand how they're using data assets. Besides being a general good practice to increase your effectiveness, understanding stakeholders and the impact of your work is a great way to make working with data more fun and engaging for both sides.
If you can't afford the time or need to do this discovery at massive organizational scale, at least find a way to automate periodic audits of code running in notebooks, BI tools, and other data compute environments.
Remediation and Prevention of Post-Production Complexity
If you've made it this far, you have everything you need to start addressing post-production complexity.
-
Iterative Improvement: Regularly update production pipelines based on user feedback and evolving business needs.
-
Monitor Complexity: Regularly review and analyze your database's audit logs to understand the most complex queries and the nature of analyses.
-
Create the right guardrails: I've talked to at least one data leader that found it valuable to create guardrails like "notebooks should never include logic to send emails".
-
Engage with Your Users: Understanding the reasons behind complex analysts on top of production models can provide insights into internal customer needs.
Do that well, and you'll go from this:
to this:
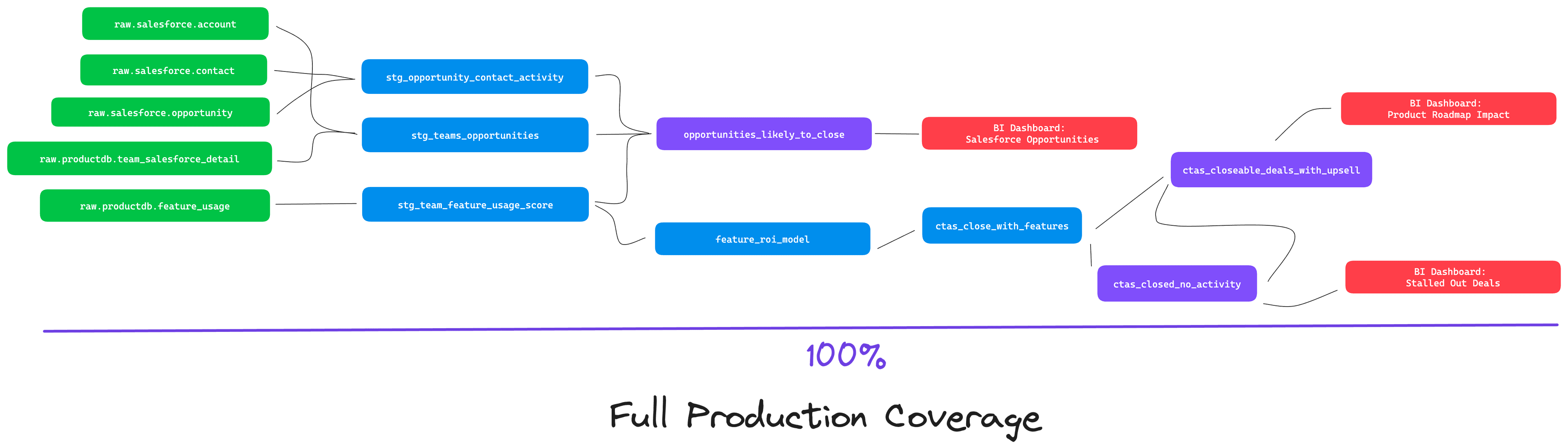
And you'll be back in the sweet spot, balancing the freedom to experiement and keeping quality efforts focused on where they matter most.
Conclusion
Getting Post-Production Complexity under control is a great way to enhance realized data quality and reliability. You'll be maximizing the amount of critical business logic that is protected by your quality measures.
Just as with Pre-Production Analytics, the key is to understand the needs of your users, and to build a data stack that supports them. It can be easy to get mad or drop a couple eyerolls whenever you find complicated logic running somewhere, but you should recognize these workloads for what they are: valuable data about what your users need. Post-production complexity is a very clear signal that what was delivered did not fully solve the users' problem.
It can be easy to get mad or drop a couple eyerolls whenever you find complicated logic running somewhere, but you should recognize these workloads for what they are: valuable data about what your users need.
My advice - when your users build up big scary analyses, don't get mad, use it as a learning opportunity. Treat analysts and stakeholders like internal customers, and every instance of this flavor of "shadow analytics" as a signal that your users need something that you're not providing. It's an invaluable chance to better understand what analysts and stakeholders need and what truly useful production data would look like.
Your stakeholders are telling you what they need.
You just have to listen for it.