Definition of Done for Data Teams
Getting intentional about the last mile of your data projectsGreat software teams are clear up front about what it means for a feature to be done.
They have a Definition of Done (DoD) that everyone agrees on.
The Definition of Done is a list of criteria that a feature must meet before it can be considered complete. It’s a way to ensure that everyone is on the same page about what it means for a feature to be done, and to make sure "afterthought" tasks like tests, documentation, and post-deployment monitoring are not forgotten.
As many people have called out, data engineering is not the same as software engineering, so setting and evolving your Definition of Done for data projects must be carefully considered. In this post, we'll explore how data teams can leverage the concept of Definition of Done to improve data quality and impact on stakeholders.
As many people have called out, data engineering is not the same as software engineering, so setting and evolving your Definition of Done for data projects must be carefully considered.
With any luck, by the end you'll be equipped to advocate for a more clear Definition of Done for your team, and you'll be well on your way to improving the quality and impact of your data projects.
Base Definition of done for software teams
The core definition of done that many software teams work to adopt includes:
- Code Complete: Code for the feature is reviewed and merged into the main branch.
- Production Deployment: The feature is deployed to production environments and customers have access to it.
- Automated Tests: The feature is covered by automated tests that are passing.
- Documentation: The feature is documented, and the documentation is reviewed and up to date.
- High Availability: The feature is reviewed from an infrastructure perspective to ensure it can scale and is highly available. Performance, load, and chaos tests are passing.
- Monitoring and Alerting: The feature is monitored and has alerting set up to notify the team if something goes wrong.
- Security Review: The feature is reviewed from a security perspective to ensure it's not introducing any new vulnerabilities and attack vectors.
- Continuous Integration: Any new services are integrated into the CI/CD pipeline and are being automatically deployed to production environments.
- Feature Flags Removed: If any feature flags were used during the delivery of the feature, they have been removed to keep the codebase clean and maintainable.
Advanced Definition of done for product-minded software teams
In addition to the above, software teams with a strong product bent will also include the following in their Definition of Done:
- Usage Instrumentation: A feature isn't done until the team has built a reliable way to know who's using it and how. Product-minded teams know that the fastest way to build the right thing is to get as much data as possible about who's using new features and how, so they never skip the step of instrumenting new features with usage metrics. Depending on scale and complexity of the feature and customer base, this could be as simple as an event in a database table or as complex as a full-fledged analytics dashboard.
A feature isn't done until the team has built a reliable way to know who's using it and how.
-
Adoption: A feature or product is not considered "done" until some number of customers are using it in production. This might be a percentage of the user base, or a certain number of customers. This is a way to ensure that the feature is actually solving a real problem for customers, and not just a hypothetical problem that the team has dreamed up. If a new feature lacks adoption, teams will get intentional about whether they continue to iterate it to improve adoption, or if they deprecate it and move on to other work. Great teams want to invest heavily in their most valuable features, and find ways to avoid spending time on anything else. The last thing you want is to spend even 10% of your bandwidth to maintain unused or poorly-adopted features.
-
Retention: Similarly - even if a feature gets strong adoption at first, great teams keep an eye on usage and behavior in the longer term. A drop-off in usage of a feature can be a strong signal that there's a technical problem with it, or that it's just no longer valuable. When this happens, great teams get intentional about when/how they prioritize either fixing the feature or deprecating it in favor of never functionality. This keeps products lean and, again, helps teams focus development efforts on the features that drive the most user value.
Great teams want to invest heavily in their most valuable features, and find ways to avoid spending time on anything else.
- Field Enablement: A feature isn't done until the sales and support teams have been trained on it, and are able to effectively sell and support it.
Definition of Done for Data Teams
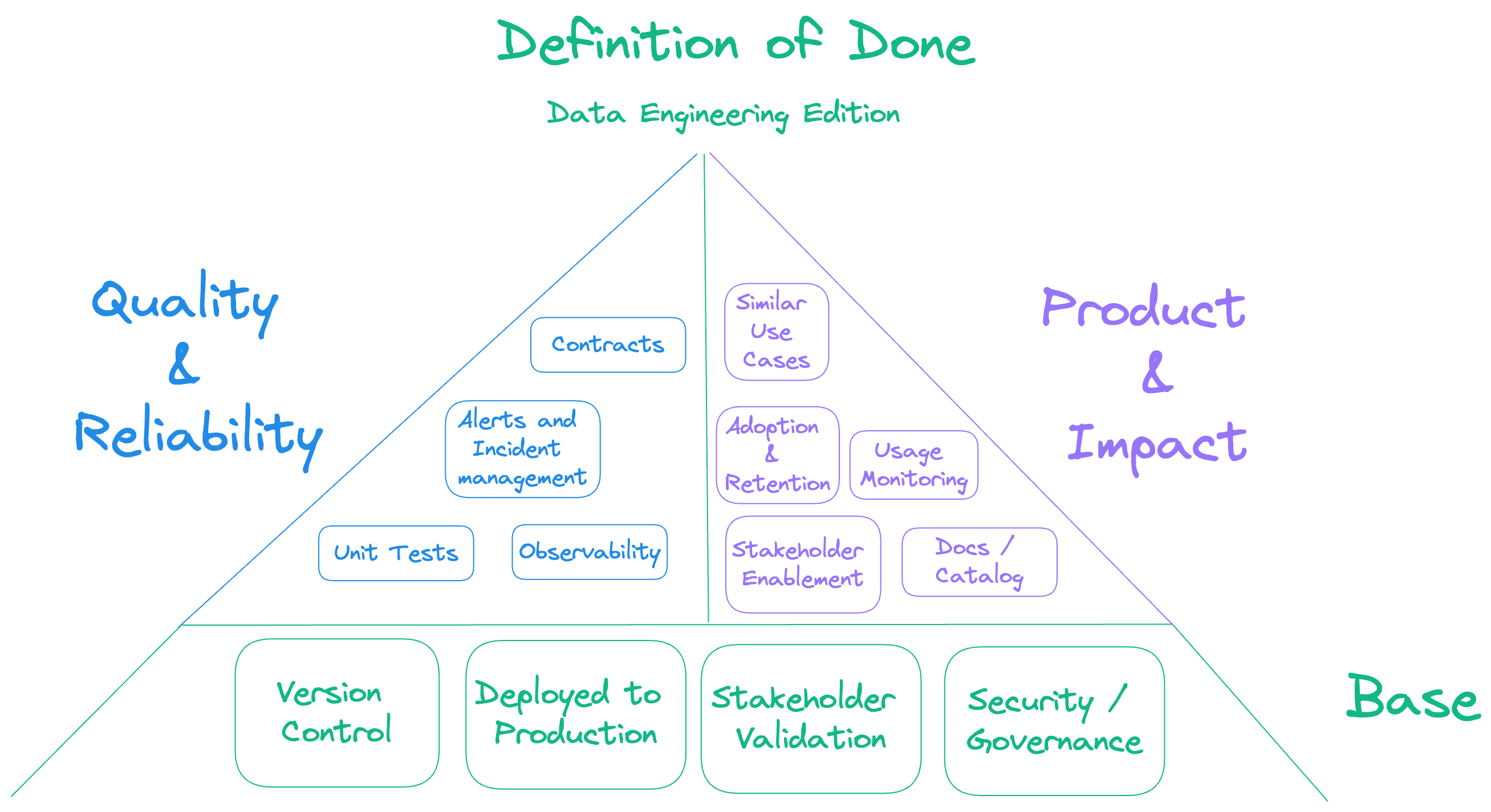
You can apply a lot of this stuff to data projects as well! As many people have called out, data engineering is not the same as software engineering, so let's dig into those differences and how they should inform your data projects.
At it's core, the Definition of Done for data projects should include the following:
-
Version Control: A report isn't done until the code that generates it is committed to version control and running on a schedule via an orchestration or modeling tool. Most of us have found out the hard way that a notebook running ETL processes on a schedule is just an incident waiting to happen.
-
Deployed to Production: A report isn't done until it's deployed to production environments.
-
Stakeholder Validation: When a report is completed, it must be validated by stakeholders to ensure it meets their needs. This could be as simple as a thumbs up from the stakeholder, or as complex as a full user acceptance test.
-
Security and Governance Review: A report isn't done until it's been reviewed from a security and governance perspective. This could include ensuring that the report doesn't expose sensitive data, or that it's been reviewed by a data governance team.
Most of us have found out the hard way that a notebook running ETL processes on a schedule is just an incident waiting to happen.
Advanced Definition of Done for Improved Data Quality
Shipping new reports is great, but if the data delivered is not reliable, then you'll have trouble getting stakeholders to trust and use it. Include the following in your definition of done for improved data quality:
-
Unit Testing: Great data teams include unit testing as part of their Definition of Done. Data Unit tests ensure that data/analytics engineers will be notified before they make changes that might break downstream reports and analyses. This is especially important for data assets that are used by many other teams, or that are used in critical business processes.
-
Data Contracts: Contracts are a special type of test framework that helps prevent upstream data producers from accidentally breaking downstream data pipelines and workflows.
-
Data Observability: Beyond explicit testing, observability platforms can monitor other potential problems like freshness issues, distribution/volume changes, and other anomaly detection. They can discover orchestration and transform issues before they break downstream workflows. Great data teams ensure these monitors are configured and tuned before calling a feature complete.
-
Alerting and Incident Management: Closely related to Observability, defining who should get paged and when is a critical aspect of improving the quality of your data assets. This will probably include tagging data assets with data quality scores. Common models use tags like "Gold", "Silver", and "Bronze" to indicate the expected quality of a data asset. Doing this well will also include establishing and testing incident management processes and how active data incidents are communicated to stakeholders.
Data Unit tests ensure that data/analytics engineers will be notified before they make changes that might break downstream reports and analyses
Advanced Definition of Done for Product-Minded data teams
Quality is great, but all the quality in the world won't matter if you're not solving real stakeholder problems. Here's how you can ensure every change to your data pipelines gets validated for impact and business value.
-
Documentation: A report isn't done until it's documented. This could be as simple as a README in the repo, or as complex as requiring column-level comments for all production SQL tables and a full-fledged data catalog. The level of documentation required will depend on the complexity of the report and the needs of analysts and stakeholders.
-
Analyst and Stakeholder Enablement: A report isn't done until the analysts and stakeholders who need it have been trained on it, and are able to effectively use it. This could include training sessions, documentation, or a full-fledged data literacy program. It's not enough to deliver what a stakeholder asked for, this is a critical step to ensure that the report is actually solving a real problem for stakeholders.
-
Validate Activation and Retention: Measure acquisition, activation, retention for data assets. Don't move onto the next project until you confirm that the data set is being used and is providing value. At the very least, check in with stakeholders for feedback during the weeks after you deliver an asset. Confirm they're still using the asset. If you discover there are issues like poor documentation, missing columns, or missing rows, be intentional about whether you abandon/deprecate/remove the work, or if you invest more time into driving usability and value. But don't just ship the thing and move on. To really scale this, compute these metrics regularly based on warehouse query logs. Set up alerts to fire when a frequently-used asset sees a significant drop in usage. These signals can help make sure you're delivering and maintaining truly valuable and usable data assets.
-
Monitor Usage: Just because an asset is being used, doesn't mean it fully solves the problem. If an asset is in use but subject to large 1000+ line queries or other extensive Post-production Complexity, then it's not done. All the quality measures you just applied will be undermined by SQL or analyses that live outside version control, contracts, observability, etc. Monitor for complex workloads and keep iterating on the data asset until it delivers value as-is.
Monitor for complex workloads and keep iterating on the data asset until it delivers value as-is.
- Migrate all similar workloads: Even if the asset is in use by certain stakeholders, you might consider holding off on calling it "done" until all potential users are educated and onboarded. For example, if you've built a pipeline for a new table that replaces an analyst's ad-hoc query, consider tracking down any other analysts / dashboards that use similar queries and getting those queries migrated to the new table. Detecting this automatically can be tricky but that's a big part of why we're building Metalytics.
Putting this into practice
It's easy to ship something, check it once, and move on to the next project. We're all busy, and it's hard to find time to do things right. But if you don't take the time to implement quality and ensure adoption, you'll risk creating a lot of technical debt and a lot of headaches for your future self and future teammates. If you want to get started, try the following:
- Talk to your team about what a good definition of done would look like for data projects
- If it's not written down yet, write it down in your teams charter or wiki
- Make a plan to build capabilities around the most important parts of your definition of done
Building new habits is hard. Don't get discouraged if folks skip tests or documentation at first. Keep talking about it and keep iterating on your definition of done until it's a habit for everyone.
If you don't take the time to implement quality and ensure adoption, you'll risk creating a lot of technical debt and a lot of headaches for your future self and future teammates.
Shameless Plug
At Metalytics, we believe strongly that there's immense value in starting from Stakeholder needs and value and working backwards from there to determine how/where data quality is implemented. We believe this is core to "running your data team like a product team", and that the data discipline has historically lacked tools to help make this possible, especially at scale.
Want to drive a stronger product mindset on your data team? Check out metalytics.dev.